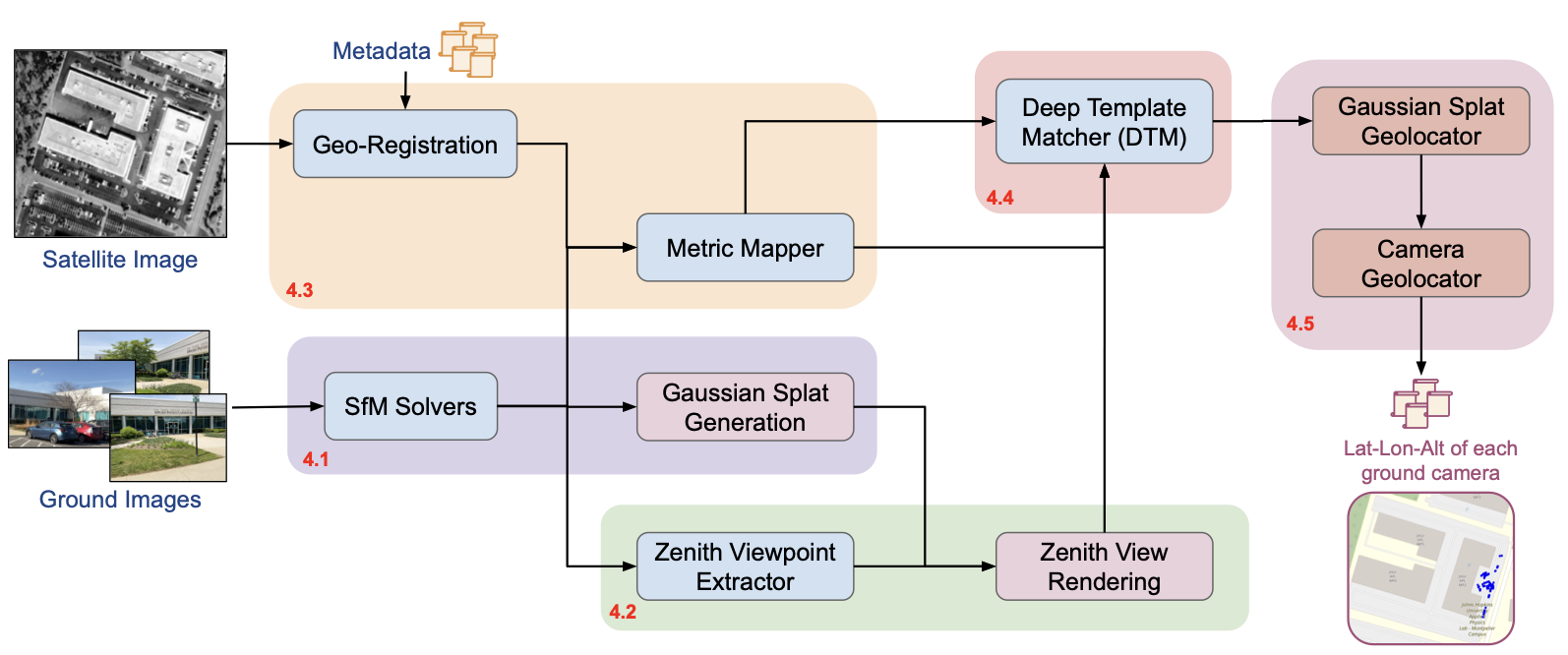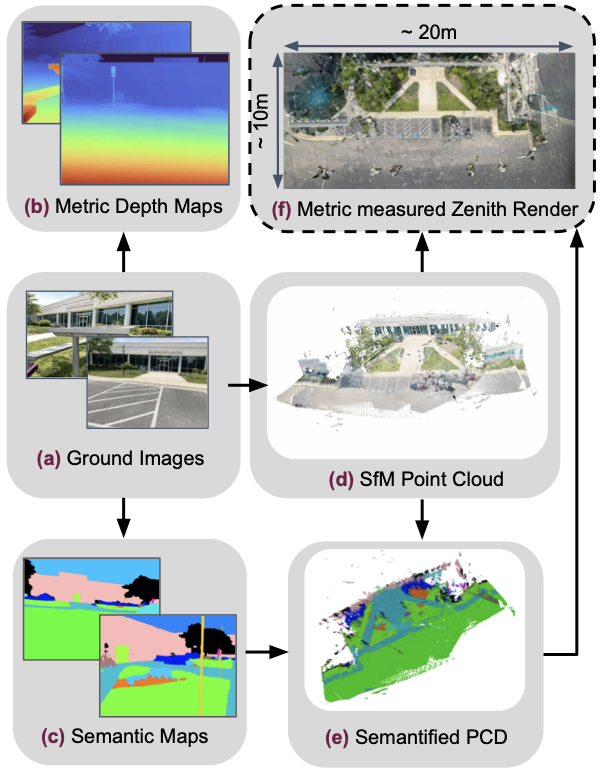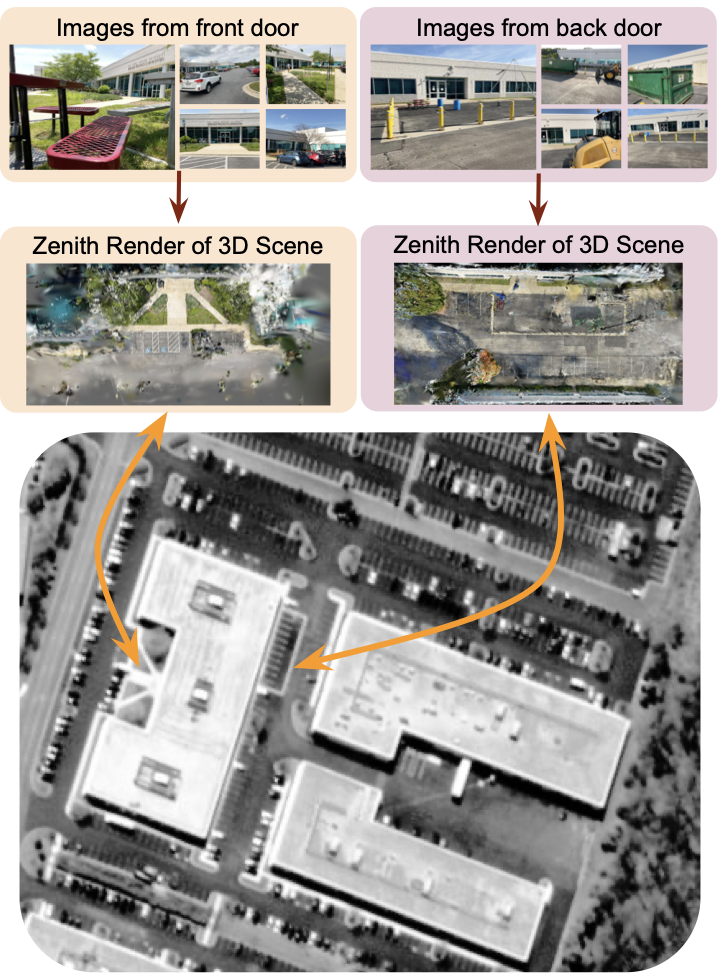
Overview of the pipeline. Directly aligning ground images to satellite views is impractical due to large viewpoint and scale differences. Wrivinder aggregates information from multiple ground images to reconstruct a 3D scene, generates a zenith-view rendering, and aligns it to the satellite image using estimated metric dimensions.